6.1. 绕过cache
当资料被产生、并且没有(立即)被再次使用时,memory储存操作会先读取完整的cache行然后修改cache资料,这点对效能是有害的。这个操作会将可能再次用到的资料踢出cache,以让给那些短期内不会再次被用到的资料。尤其是像矩阵 –– 它会先被填值、接著才被使用 –– 这类大资料结构。在填入矩阵的最后一个元素前,第一个元素就会因为矩阵太大被踢出cache,导致写入cache丧失效率。
对于这类情况,处理器提供对非暂存(non-temporal)写入操作的支援。这个情境下的非暂存指的是资料在短期内不会被使用,所以没有任何cache它的理由。这些非暂存的写入操作不会先读取cache行然后才修改它;反之,新的内容会被直接写进memory。
这听来代价高昂,但并不是非得如此。处理器会试著使用合并写入(见 3.3.3 节)来填入整个cache行。若是成功,那么memory读取操作是完全不必要的。如 x86 以及 x86-64 架构,gcc 提供若干 intrinsic 函式 译注:
#include <emmintrin.h>
void _mm_stream_si32(int *p, int a);
void _mm_stream_si128(int *p, __m128i a);
void _mm_stream_pd(double *p, __m128d a);
#include <xmmintrin.h>
void _mm_stream_pi(__m64 *p, __m64 a);
void _mm_stream_ps(float *p, __m128 a);
#include <ammintrin.h>
void _mm_stream_sd(double *p, __m128d a);
void _mm_stream_ss(float *p, __m128 a);
最有效率地使用这些指令的情况是一次处理大量资料。资料从memory载入、经过一或多步处理、而后写回memory。资料「流(stream)」经处理器,这些指令便得名于此。
memory位置必须各自对齐至 8 或 16 位元组。在使用多媒体扩充(multimedia extension)的程序码中,也可以用这些非暂存的版本替换一般的 _mm_store_* 指令。我们并没有在 A.1 节的矩阵相乘程序中这么做,因为写入的值会在短时间内被再次使用。这是串流指令无所助益的一个例子。6.2.1 节会更加深入这段程序码。
处理器的合并写入缓冲区可以将部分写入cache行的请求延迟一小段时间。一个接著一个执行所有修改单一cache行的指令,以令合并写入能真的发挥功用通常是必要的。以下是一个如何实践的例子:
#include <emmintrin.h>
void setbytes(char *p, int c)
{
__m128i i = _mm_set_epi8(c, c, c, c,
c, c, c, c,
c, c, c, c,
c, c, c, c);
_mm_stream_si128((__m128i *)&p[0], i);
_mm_stream_si128((__m128i *)&p[16], i);
_mm_stream_si128((__m128i *)&p[32], i);
_mm_stream_si128((__m128i *)&p[48], i);
}
假设指标 p 被适当地对齐,呼叫这个函式会将指向的cache行中的所有位元组设为 c。合并写入逻辑会看到四个生成的 movntdq 指令,并仅在最后一个指令被执行之后,才对memory发出写入命令。总而言之,这段程序不仅避免在写入前读取cache行,也避免cache被并非立即需要的资料污染。这在某些情况下有著巨大的好处。一个经常使用这项技术的例子即是 C 函式库中的 memset 函式,它在处理大块memory时应该要使用类似于上述程序的作法。
某些架构提供专门的解法。PowerPC 架构定义 dcbz 指令,它能用以清除整个cache行。这个指令不会真的绕过cache,因为cache行仍会被分配来存放结果,但没有任何资料会从memory被读出来。这相比于非暂存储存指令更加受限,因为cache行只能全部被清空而污染cache(在资料为非暂存的情况),但其不需合并写入逻辑来达到这个结果。
为了一探非暂存指令的运作,我们将观察一个用以测量矩阵 –– 由一个二维阵列所组成 –– 写入效能的新测试。编译器将矩阵置放于memory中,以令最左边的(第一个)索引指向一列在memory中连续置放的所有元素。右边的(第二个)索引指向一列中的元素。测试程序以两种方式迭代矩阵:第一种是在内部回圈增加行号,第二种是在内部回圈增加列号。这代表其行为如图 6.1 所示。
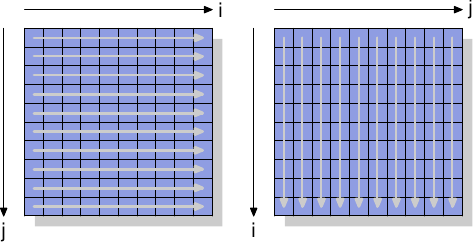
我们测量初始化一个 3000 × 3000 矩阵所花的时间。为了观察memory的表现,我们采用不会使用cache的储存指令。在 IA-32 处理器上,「非暂存提示(non-temporal hint)」即被用在于此。作为比较,我们也测量一般的储存操作。结果见于表 6.1。
| 内部回圈增加 | ||
|---|---|---|
| 列 | 行 | |
| 一般 | 0.048s | 0.127s |
| 非暂存 | 0.048s | 0.160s |
对于使用cache的一般写入操作,我们观察到预期中的结果:若是memory被循序地使用,我们会得到比较好的结果,整个操作费 0.048s,相当于 750MB/s,几近于随机存取的情况却花 0.127s(大约 280MB/s)。这个矩阵已经大到令cache没那么有效。
我们感兴趣的部分主要是绕过cache的写入操作。可能令人吃惊的是,在这里循序存取跟使用cache的情况一样快。这个结果的原因是处理器执行上述的合并写入操作。此外,对于非暂存写入的memory排序(memory ordering)规则亦被放宽:程序需要明确地插入memory屏障(memory barriers)(如 x86 与 x86-64 处理器的 sfence 指令)。意味著处理器在写回资料时有著更多的自由,因此能尽可能地善用可用的频宽。
内部回圈以行向(column-wise)存取的情况就不同。无cache存取的结果明显地慢于cache存取(0.16s,约 225MB/s)。这里我们可以理解到,合并写入是不可能的,每个记忆单元都必须被独立处理。这需要不断地从 RAM 晶片上选取新的几列,附带著与此相应的延迟。结果是比有cache的情况还慢 25%。
在读取操作上,处理器 –– 直到最近 –– 除了非暂存存取(Non-Temporal Access,NTA)预取指令的弱提示之外,仍欠缺相应的支援。没有与合并写入对等的读取操作,这对诸如memory对映 I/O(memory-mapped I/O)这类无法被cache的memory尤其糟糕。Intel 附带 SSE4.1 扩充引入 NTA 载入。它们以一些串流载入缓冲区(streaming load buffer)实作;每个缓冲区包含一个cache行。针对一个cache行的第一个 movntdqa 指令会将cache行载入一个缓冲区 –– 可能会替换掉另一个cache行。随后,对同一个cache行、以 16 位元组对齐的存取操作将会由载入缓冲区以少量的成本来提供服务。除非有其它理由,cache行将不会被载入到cache中,于是便能够在不污染cache的情况下载入大量的memory。编译器为这个指令提供一个 intrinsic 函式:
#include <smmintrin.h>
__m128i _mm_stream_load_si128 (__m128i *p);
这个 intrinsic 函式应该要以 16 位元组区块的地址做为参数执行多次,直到每个cache行都被读取为止。在这时才应该开始处理下一个cache行。由于只有少数几个串流读取缓冲区,可能要一次从两个memory位置进行读取。
我们应该从这个实验得到的是,现代的 CPU 非常巧妙地最佳化无cache写入 –– 近来甚至包括读取操作,只要它们是循序操作的。在处理只会被用到一次的大资料结构时,这个知识是非常有用的。再者,cache能够降低一些 –– 但不是全部 –– 随机memory存取的成本。在这个例子中,由于 RAM 存取的实作,导致随机存取慢 70%。在实作改变以前,无论何时都应该避免随机存取。
我们将会在谈论预取的章节再次一探非暂存旗标。
译注. intrinsic 函式可简称 intrinsics,由编译器提供,类似 inline 函式,但跟微处理器架构紧密相关,因为编译器知道如何运用最佳的方式来输出对应的微处理器指令。有些状况下,intrinsics 可能会呼叫标准函式库或执行环境的函式,甚至可能会有跨越处理器之间 intrinsics 的转换,例如译者维护的 SSE2NEON 专案。 ↩