3.5.2. 关键字组的载入
memory以比cache行大小还小的区块从主memory传输到cache中。现今是一次传输 64 位元,而cache行的大小为 64 或 128 位元组。这表示每个cache行需要 8 或 16 次传输。
DRAM 晶片能够以突发(burst)模式传输那些 64 位元组的区块。这能够在没有来自memory控制器的额外命令、以及可能伴随的延迟的情况下填满cache行。若是处理器预取cache行,这可能是最好的操作方式。
若是一支程序的资料或cache存取没有命中(这表示,这是个强制性cache错失〔compulsory cache miss〕–– 因为资料是第一次使用、或者是容量性cache错失〔capacity cache miss〕–– 因为受限的cache大小需要逐出cache行),情况便不同。程序继续执行所需的cache行里头的字组也许不是cache行中的第一个字组。即使在突发模式下、并以双倍资料速率来传输,个别的 64 位元区块也会在明显不同的时间点抵达。每个区块会在前一个区块抵达之后 4 个 CPU 周期以上抵达。若是程序继续执行所需的字组是cache行的第八个,程序就必须在第一个字组抵达之后,等待额外的 30 个周期以上。
事情并不必然非得如此。memory控制器能够以不同的顺序随意请求cache行的字组。处理器能够传达程序正在等待哪个字组 –– 即关键字组,而memory控制器能够先请求这个字组。一旦这个字组抵达,程序便能够在cache行其余部分抵达、并且cache还不在一致状态的期间继续执行。这个技术被称为关键字组优先与提早重新启动(Critical Word First & Early Restart)。
现今的处理器实作这项技术,但有些不可能达成的情况。若是处理器预取资料,并且关键字组是未知的。万一处理器在预取操作的途中请求这个cache行,就必须在不能够影响顺序的情况下,一直等到关键字组抵达为止。
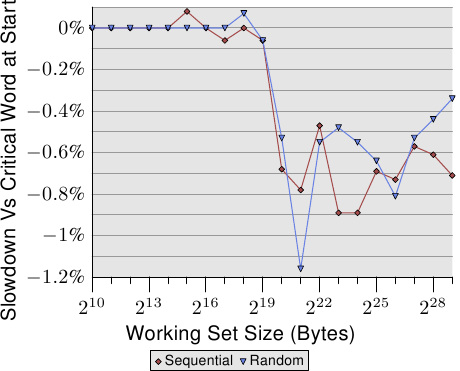
即使在适当的地方有了这些最佳化,关键字组在cache行的位置也很重要。图 3.30 显示循序与随机存取的 Follow 测试结果。显示的是以用来巡访的指标位在第一个字组来执行测试,对比指标位在最后一个字组的情况下的速度减慢的结果。元素大小为 64 位元组,与cache行的大小一致。数字受到许多杂讯干扰,但能够看到,一旦 L2 不再足以持有工作集大小,关键字组在末端时的效能立刻就慢约 0.7%。循序存取似乎受到多一点影响。这与前面提及的、预取下个cache行时的问题一致。