5.4. 远端存取成本
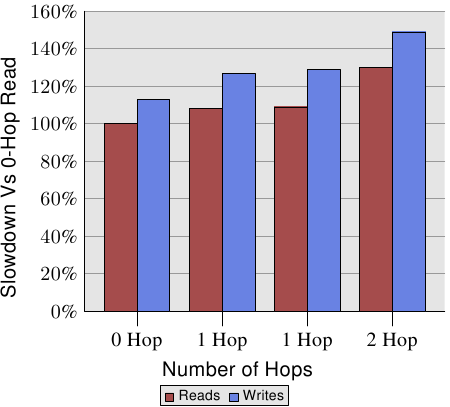
不过,距离是有关系的。AMD 在 [1] 提供了一台四槽机器的 NUMA 成本的文件。写入操作的数据显示在图 5.2。写入比读取还慢,这并不让人意外。有趣的部分在于 1 与 2 跳(1- and 2-hop)情况下的成本。两个 1 跳的成本实际上有略微不同。细节见 [1]。2 跳读取与写入(分别)比 0 跳读取慢了 30% 与 49%。2 跳写入比 0 跳写入慢了 32%、比 1 跳写入慢了 17%。处理器与memory节点的相对位置能够造成很大的差距。来自 AMD 下个世代的处理器将会以每个处理器四条连贯的超传输连结为特色。在这个例子中,一台四槽机器的直径会是一。但有八个插槽的话,同样的问题又 –– 来势汹汹地 –– 回来了,因为一个有著八个节点的超立方体的直径为三。
所有这些资讯都能够取得,但用起来很麻烦。在 6.5 节,我们会看到较容易存取与使用这个资讯的介面。
00400000 default file=/bin/cat mapped=3 N3=3
00504000 default file=/bin/cat anon=1 dirty=1 mapped=2 N3=2
00506000 default heap anon=3 dirty=3 active=0 N3=3
38a9000000 default file=/lib64/ld-2.4.so mapped=22 mapmax=47 N1=22
38a9119000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a911a000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a9200000 default file=/lib64/libc-2.4.so mapped=53 mapmax=52 N1=51 N2=2
38a933f000 default file=/lib64/libc-2.4.so
38a943f000 default file=/lib64/libc-2.4.so anon=1 dirty=1 mapped=3 mapmax=32 N1=2 N3=1
38a9443000 default file=/lib64/libc-2.4.so anon=1 dirty=1 N3=1
38a9444000 default anon=4 dirty=4 active=0 N3=4
2b2bbcdce000 default anon=1 dirty=1 N3=1
2b2bbcde4000 default anon=2 dirty=2 N3=2
2b2bbcde6000 default file=/usr/lib/locale/locale-archive mapped=11 mapmax=8 N0=11
7fffedcc7000 default stack anon=2 dirty=2 N3=2/proc/PID/numa_maps 的内容系统提供的最后一块资讯就在行程自身的状态中。能够确定memory映射档、写时复制(Copy-On-Write,COW)27分页与匿名memory(anonymous memory)是如何散布在系统中的节点上的。系统核心为每个处理器提供一个虚拟档(pseudo-file) /proc/PID/numa_maps,其中 PID 为行程的 ID ,如图 5.3 所示。档案中的重要资讯为 N0 到 N3 的值,它们表示为节点 0 到 3 上的memory区域分配的分页数量。一个可靠的猜测是,程序是执行在节点 3 的核上。程序本身与被弄脏的分页被分配在这个节点上。唯读映射,像是 ld-2.4.so 与 libc-2.4.so 的第一次映射、以及共享档案 locale-archive 是被分配在其它节点上的。
如同我们已经在图 5.2 看到的,当横跨节点操作时,1 与 2 跳读取的效能分别掉了 9% 与 30%。对执行来说,这种读取是必须的,而且若是没有命中 L2 cache的话,每个cache行都会招致这些额外成本。若是memory离处理器很远,对超过cache大小的大工作负载而言,所有量测的成本都必须提高 9%/30%。
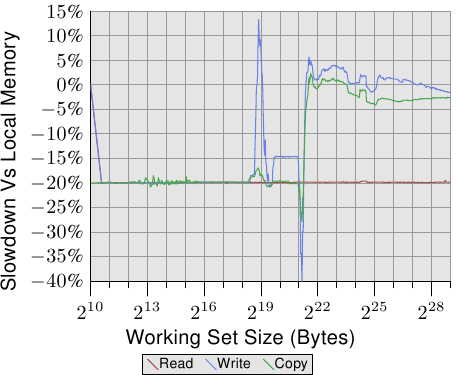
为了看到在现实世界的影响,我们能够像 3.5.1 节一样测量频宽,但这次使用的是在远端、相距一跳的节点上的memory。这个测试相比于使用本地memory的数据的结果能在图 5.4 中看到。数字在两个方向都有一些大起伏,这是一个测量多执行绪程序的问题所致,能够忽略。在这张图上的重要资讯是,读取操作总是慢了 20%。这明显慢于图 5.2 中的 9%,这极有可能不是连续读/写操作的数字,而且可能与较旧的处理器修订版本有关。只有 AMD 知道了。
以塞得进cache的工作集大小而言,写入与复制操作的效能也慢了 20%。当工作集大小超过cache大小时,写入效能不再显著地慢于本地节点上的操作。互连的速度足以跟上memory的速度。主要因素是花费在等待主memory的时间。
27. 当一个memory分页起初有个使用者,然后必须被复制以允许独立的使用者时,写时复制是一种经常在操作系统实作用到的方法。在许多情境中,复制 –– 起初或完全 –– 是不必要的。在这种情况下,只在任何一个使用者修改memory的时候复制是合理的。操作系统拦截写入操作、复制memory分页、然后允许写入指令继续执行。 ↩